2026. 5. 18. 14:02ㆍ업무/데이터과학
Time-LLM: LLM을 다시 프로그래밍하여 시계열 예측을 하는 모델 (Time Series Forecasting by Reprogramming Large
PyTorchKR🔥🇰🇷 🤔💬 개인적으로 관심이 있지만 이래저래 손을 못 대고 있었던 시계열 예측(Time-series Forecasting) 분야에서 LLM을 끼얹은(...) 논문을 발견하여 정리해보았습니다. 까먹고 있었는
discuss.pytorch.kr
https://arxiv.org/abs/2310.01728v2?utm_source=pytorchkr&ref=pytorchkr
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
Time series forecasting holds significant importance in many real-world dynamic systems and has been extensively studied. Unlike natural language process (NLP) and computer vision (CV), where a single large model can tackle multiple tasks, models for time
arxiv.org
Time-LLM은 시계열 데이터를 텍스트 기반의 표현으로 변환한 뒤 이를 LLM에 학습시키는 방식을 활용합니다. 즉, LLM의 기존의 언어 처리 기능을 시계열 예측에 활용한 것으로, 시계열 데이터를 텍스트 형태로 변경 / 접두사형 프롬프트(PaP, Prompt-as-Prefix)를 사용한 요청, 결과 텍스트를 다시 시계열 데이터로 변경하는 과정을 거쳐서 예측을 하게 됩니다.
시계열 데이터의 미래 가치를 정확하게 예측하는 것은 금융, 마케팅, 자원 관리, 과학 연구 등 다양한 분야에서 매우 중요하지만, 기존의 예측 방법은 복잡한 데이터 패턴으로 인해 어려움을 겪거나 전문 지식이 필요한 경우가 대부분이었습니다. 통계 모델이나 머신러닝 알고리즘과 같은 전통적인 방법은 널리 사용되지만 데이터의 미묘한 뉘앙스를 포착하지 못할 수 있는데 반해, Time-LLM은 새로운 가능성을 제시합니다.
LLM 재프로그래밍(LLM Reprogramming)이란?

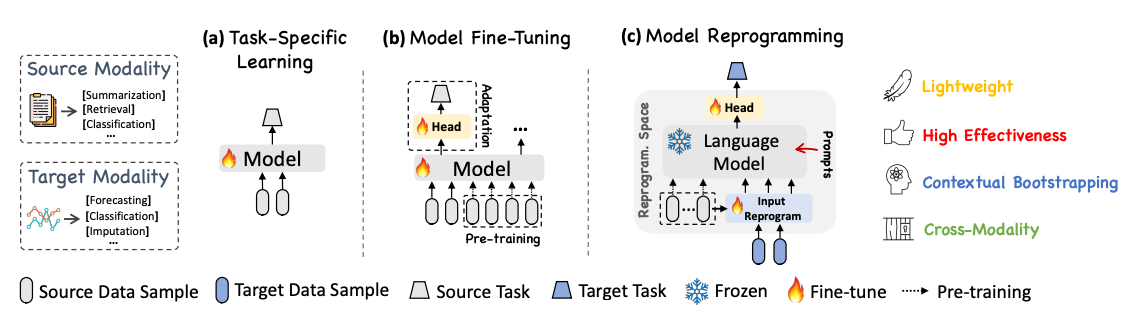
기존의 시계열 예측 방법들은 주로 특정 작업을 위해 설계된 알고리즘을 활용하고 있어, 예측 알고리즘과 데이터 특성에 대한 전문 지식을 필요로하는 것이 일반적이었습니다. 하지만, Time-LLM에서 접근한 'LLM 재프로그래밍(LLM reprogramming)' 방식을 사용하면 광범위한 파인튜닝이나 재학습 없이 원하는 시계열 예측 방법에 사용할 수 있게됩니다. Time-LLM의 구조에 대해서 살펴보기 전에 LLM 재프로그래밍 기법에 대해서 먼저 살펴보도록 하겠습니다.
LLM 재프로그래밍 기법은 기본적으로 방대한 양의 텍스트 데이터로 학습된 LLM이 시계열 예측을 수행하도록 약간의 '기교(trick)'를 부리는 것과 같습니다. 즉, LLM을 처음부터 다시 훈련시키는 대신, 언어 처리 및 패턴 인식에 대한 기존 기술을 새로운 작업에 맞게 용도를 변경하는 데 중점을 둡니다.
LLM 재프로그래밍은 다음과 같은 방식으로 동작합니다:
- 데이터 변환(Data Transformation): 원본 시계열 데이터는 기호 기반 인코딩, 패턴 기반 인코딩 또는 자연어 설명 통합과 같은 다양한 기술을 사용하여 텍스트 표현으로 변환됩니다. 이렇게 하면 LLM이 이해할 수 있는 '언어'가 만들어집니다.
- 접두사형 프롬프트(PaP, Prompt-as-Prefix): 프롬프트라고 하는 특정 지침이 텍스트 데이터와 함께 LLM에 제공됩니다. 이러한 프롬프트는 예측 대상, 도메인 지식 통합, 관련 패턴 강조 표시 등을 지정하여 예측 작업에 대한 LLM의 주의와 추론을 유도합니다.
- LLM을 사용한 예측(Inference using LLM): LLM은 텍스트 데이터와 프롬프트를 분석하여 언어 처리 기능을 활용하여 데이터 내의 패턴과 관계를 식별합니다. 기본적으로 인코딩된 시계열을 '읽고' 의미 있는 정보를 추출합니다.
- 출력 투영(Output Projection): 그런 다음 LLM의 예측 결과인 텍스트는 출력 투영이라는, 일종의 '디코딩(decoding)' 과정을 거쳐 다시 숫자로 변환됩니다. 이를 통해 실제 애플리케이션에서 예측을 직접 해석하고 사용할 수 있습니다.
Time-LLM에서 적용한 LLM 재프로그래밍은 사전 학습된 LLM의 능력을 활용하는 방법으로, (1) 각 작업별로 모델을 학습하는 방식(task-specific learning)보다 유연성이 뛰어나고 일반화하된 방식으로 사용할 수 있습니다. 또한, (2) 모델을 파인튜닝하는 방식(model fine-tuning)에 비해 기본 모델의 잠재력을 충분히 활용할 수 있으며, 적용하고자 하는 세부 작업별로 파인튜닝을 하지 않아도 된다는 장점이 있습니다. 하지만, 최적의 성능을 위해서는 텍스트 인코딩 및 프롬프트의 신중한 설계가 필요하며, 아직은 모든 작업에서 전문화된 모델을 능가하지는 못한다는 약점도 함께 가지고 있습니다.
Time-LLM 모델 구조

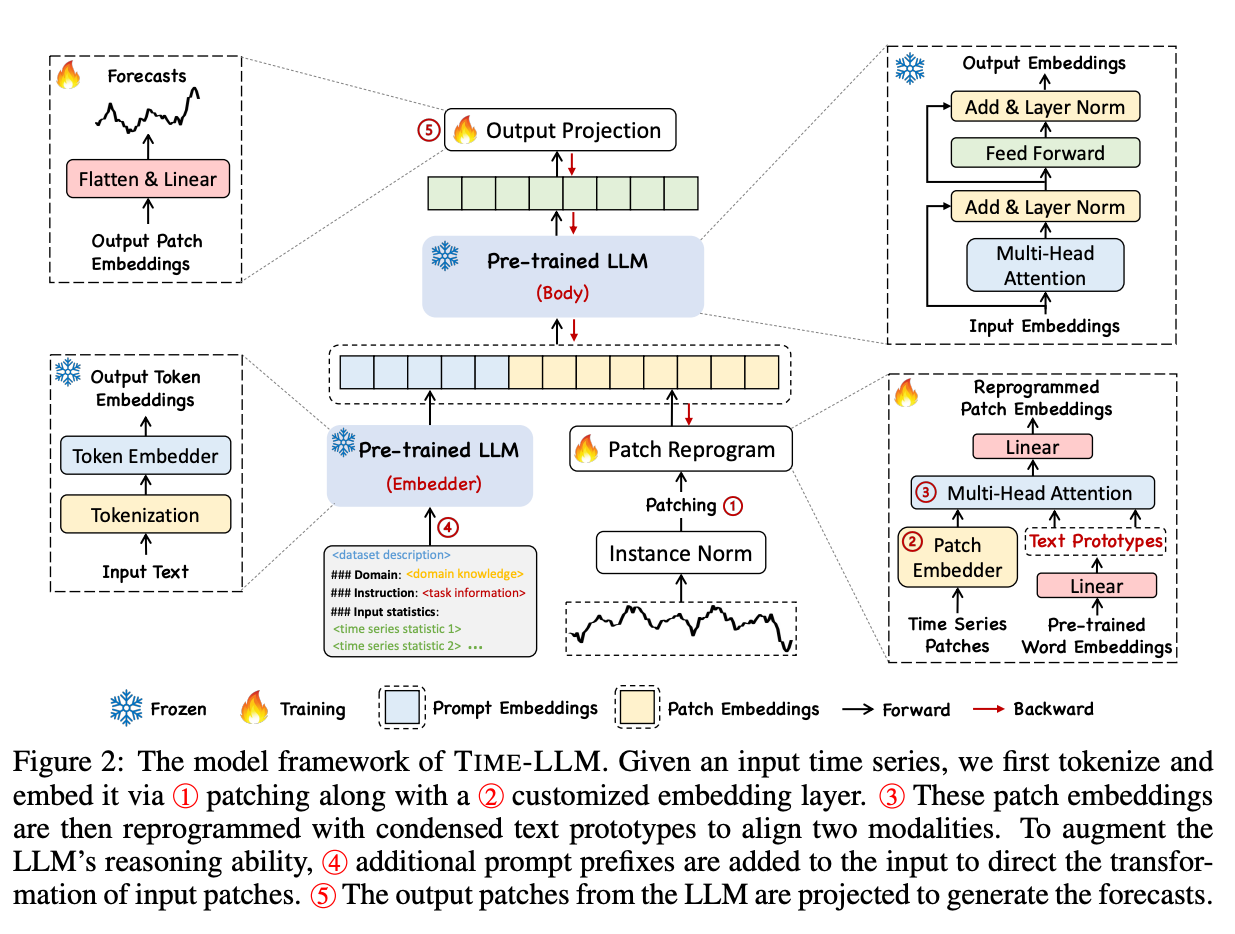
Time-LLM의 핵심은 시계열 예측 작업을 위해 기존의 대규모 언어 모델(LLM)을 다시 프로그래밍하는 기능에 있습니다. 어떻게 이러한 접근 방법이 가능한지에 대해서 살펴보겠습니다.
입력 임베딩(Input Embedding)
먼저 입력으로 사용할 시계열 데이터를 준비합니다. 이러한 원본 시계열 데이터를 텍스트로 인코딩하기 전, 모델과의 호환성과 일관성을 유지하기 위해 전처리 및 정제하는 과정을 거칩니다. 이러한 전처리 과정에는 결측값(missing value)이나 이상치(outlier) 처리, 데이터 스케일링 및 정규화(scaling / normalizing) 등이 포함되어 있습니다.
전처리가 완료된 시계열 데이터가 준비되었다면, 이제 LLM이 이해할 수 있도록 텍스트로 인코딩합니다. 서로 다른 시점의 숫자 값으로 구성된 시계열 데이터는 LLM이 직접 이해할 수 없습니다. 이 간극을 메우기 위해 Time-LLM은 텍스트 인코딩 기법을 사용합니다. 여기에는 숫자 데이터를 일련의 기호와 패턴으로 변환하여 LLM이 "언어"로 해석할 수 있도록 하는 작업이 포함됩니다.
다음은 데이터의 특성과 작업의 종류에 따른 몇 가지 일반적인 인코딩 기법의 예시들입니다:
- 기호 기반 인코딩(Symbol-based encoding): 각 데이터 포인트는 고유한 기호로 표시되며, 일련의 기호는 시계열 패턴을 인코딩합니다.
- 패턴 기반 인코딩(Pattern-based encoding): 추세(trend), 계절성(seasonality) 또는 주기(cycle)와 같은 특정 패턴이 식별되고 기호로 표시되어 LLM이 이러한 역학을 포착할 수 있습니다.
- 자연어 인코딩(Natural Language encoding): 텍스트 설명이나 관련 이벤트가 있는 시계열의 경우, 이러한 요소를 텍스트 표현에 직접 통합하여 LLM에 더 풍부한 컨텍스트를 제공할 수 있습니다.
인코딩 방법의 선택은 Time-LLM의 효과에 결정적인 역할을 합니다. 신중하게 설계된 인코딩은 LLM이 데이터 내의 기본 패턴과 관계를 이해하는 데 필요한 정보를 수신할 수 있도록 보장합니다.
패치 재프로그래밍(Patch Reprogramming)
(시계열 → 텍스트로) 인코딩된 데이터를 패치(patch)라고 불리는 일정한 크기의 데이터 조각(segment)로 나눕니다. LLM은 이러한 패치를 입력으로 받아 데이터를 처리하게 됩니다. 기존의 언어 모델과 동일하게 입력 값(여기서는 패치)은 임베딩 레이어를 거쳐 다차원의 임베딩 벡터로 변환되며, 이 과정에서 패치 내부의 의미있는 데이터와 관계가 표현되게 됩니다.
이를 위해 인코딩된 시계열 데이터의 관계 식별을 위한 어텐션을 아래와 같은 방식으로 정리합니다. 아래 수식에서 𝑄(𝑖)𝑘, 𝐾(𝑖)𝑘, 𝑉(𝑖)𝑘 는 𝑖 번째 레이어에서의 Key, Query, Value 벡터이며, 𝑍(𝑖)𝑘 는 현재 예측 작업과 가장 관련성 높은 부분의 인코딩된 데이터의 가중합을 나타냅니다. (자세한 내용은 5페이지의 수식(1)을 참고해주세요. )
이러한 어텐션 메커니즘을 통해 Time-LLM은 인코딩된 시계열 데이터 중 현재 예측 작업과 가장 관련성이 높은 특정 부분에 집중할 수 있습니다. 시계열 데이터에는 복잡한 패턴과 종속성이 포함되어 있는 경우가 많고 모든 데이터 포인트가 정확한 예측을 위해 똑같이 중요한 것은 아니기 때문에 이 기능은 매우 중요합니다. 가장 관련성이 높은 정보에 선택적으로 관심을 기울이면 모든 데이터 요소를 동일하게 처리하는 방법에 비해 Time-LLM이 더 나은 예측 성능을 달성할 수 있습니다.
접두사형 프롬프트 (PaP, Prompt-as-Prefix)
이전 단계의 텍스트 인코딩은 LLM이 시계열 데이터를 처리할 수 있게 해주지만, LLM이 입력된 데이터로 "무엇을 해야 하는지"는 명시하지 않습니다. 바로 이 부분에서 PaP(Prompt-as-Prefix, 접두사형 프롬프트)가 등장합니다. PaP는 인코딩된 데이터와 함께 LLM에 전달되는 일련의 명령어 또는 프롬프트 역할을 합니다.

{kind=link}
{kind=link}
{kind=link}
Time-LLM으로 처리하고자 하는 작업 유형(예. 미래 값 예측, 이상징후 감지 등)에 맞춰 프롬프트 템플릿을 설계하고, LLM이 이러한 프롬프트를 처리하며 원하는 작업 유형에 맞는 추론이 되도록 유도합니다. 이를 위해 프롬프트를 구성하는 단계와 각 패치 앞에 해당 프롬프트를 앞에 붙이는(prefix) 단계를 거칩니다.
이러한 프롬프트는 다음을 통해 LLM의 분석을 안내합니다:
- 예측 작업 지정: 미래 값 예측, 추세 파악, 이상 징후 감지 등 다양한 예측 작업을 수행할 수 있습니다.
- 도메인 지식 제공: 데이터 소스, 컨텍스트 또는 특정 예측 목표에 대한 관련 정보를 통합합니다.
- 어텐션 유도: LLM이 집중해야 할 데이터 내의 특정 패턴이나 특징을 강조 표시합니다.
개발자는 PaP 프롬프트를 효과적으로 작성함으로써 LLM의 동작을 원하는대로 조작할 수 있으며, 정확하고 관련성 있는 예측을 하도록 유도할 수 있습니다.
출력 투영(Output Projection)
인코딩된 데이터에 PaP를 포함하여 LLM에 추론을 요청하면 결과를 얻을 수 있습니다. LLM은 방대한 언어 처리 능력을 바탕으로 텍스트 표현을 분석하여 다음과 같은 작업을 수행합니다:
- 데이터 내에서의 패턴과 관계 식별: LLM은 텍스트를 분석하는 방식과 유사하게 데이터 내에서 반복되는 시퀀스, 상관관계, 종속성을 검색합니다.
- 컨텍스트에 기반한 추론: PaP 프롬프트는 컨텍스트를 제공하고 LLM의 추론 프로세스를 안내하여 미래 값에 대해 정보에 입각한 예측을 할 수 있도록 합니다.
- 텍스트 기반 예측 생성: LLM의 출력은 처음에 선택한 인코딩 방법에 맞춰 텍스트 예측의 형태로 제공됩니다.
이렇게 제공된 LLM의 예측을 텍스트 데이터에서 원래 시계열 데이터와 관련된 수치로 다시 변환하는 것입니다. 출력 투영(Output Projection)이라 부르는 과정을 통해 예측을 직접 해석할 수 있고 실제 애플리케이션에 사용할 수 있습니다.
인코딩 시에 사용했던 방법과 원하는 출력 형식에 따라 다양한 투영 기법을 사용할 수 있습니다. 예를 들어, 인코딩에 기호가 사용된 경우(Symbol-based Encoding), 매핑 체계가 이를 다시 숫자 값으로 변환합니다. 패턴을 인식하여 인코딩된 경우(Pattern-based Encoding)에는 식별된 패턴을 기반으로 원래의 시계열을 재구성하는 투영 기법이 사용될 수 있습니다.
'업무 > 데이터과학' 카테고리의 다른 글
| Apache Jena + Spring Boot 온톨로지 SPARQL API [클로드 코드] 정리 (0) | 2026.04.23 |
|---|---|
| 정형 + 비정형 데이터를 활용한 이상 탐지/예측 ML 시스템 아키텍처 설계 [클로드 코드] 정리 (0) | 2026.04.22 |
| LLM as a Judge (0) | 2026.01.16 |
| Self-corrective RAG(control flow) (0) | 2025.12.23 |
| Improving Language Understanding by Generative Pre-Training (0) | 2025.09.12 |